
클라우드 전문정보
| 제목 | [2부] 배포된 머신 러닝 모델에 대한 실시간 통찰력을 제공하는 Amazon SageMaker Model Monitor | ||
|---|---|---|---|
| 등록일 | 2025-07-07 | 조회수 | 329 |

상명대학교 / 서광규 교수
4. 모델 모니터링 방법론
모델 모니터에서 드리프트 감지의 기본 방법론을 살펴보면 다음과 같다.
4-1. 핵심 방법론 : 데이터 스케치
지표를 기록할 때 유용한 개념은 데이터 스케치이다. 이를 설명하기 위해 단일 숫자를 출력하는 회귀 모델이 있고 시간 경과에 따른 평균을 모니터링하려는 간단한 예를 들어 설명하면 다음과 같다.
스케치는 숫자 스트림이 입력되는 객체이다. 스케치는 (i) 관측된 총 숫자의 양인 tot과 (ii) 지금까지 관측된 숫자의 합인 sum을 유지한다. 관측된 모든 모델 출력에 대해 내부 상태, 즉 tot에 1을 더하고 sum에 값을 더한다. 언제든지 이 스케치에서 현재 평균을 쿼리할 수 있으며, tot, sum을 포함하는 내부 상태를 최종값으로 반환한다. 이 경우 sum/tot를 계산한다. 동일한 모델을 호스팅하는 두 대의 머신이 있는 경우, 두 머신 모두 tot, sum의 로컬 복사본을 포함하는 내부 상태를 가지며, 전체 평균을 쿼리할 때 각각의 tot, sum을 더하여 단일 상태로 병합하고 해당 상태를 최종화하여 전체 평균을 제공한다. 사용자가 최대 1시간까지 서로 다른 시간 간격으로 평균을 쿼리하려는 경우, 매 시간마다 상태를 저장할 수 있으며, X시간 연속 간격에 대한 쿼리가 주어지면 관련 상태를 병합하고 병합된 상태를 최종화한 후 평균을 반환한다.
이 패러다임은 평균 계산이라는 이 간단한 예시를 넘어 확장되며, 다양한 지표 계산에 사용된다. 이 패러다임은 때로는 평균, 표준 편차, 누락된 항목의 개수 또는 비율과 같은 지표에 대해 간단하게 적용할 수 있다. 다른 경우에는 정확한 측정값을 얻는 것이 더 어렵거나 심지어 불가능하다. 예를 들어, 관찰값의 히스토그램이나 중앙값만 유지하려는 경우, 모든 관측 항목을 저장하지 않고는 정확한 지표를 얻는 것이 불가능하다는 것이 알려져 있다. 다행히도 근사값은 거의 항상 유효하며, 사용자는 정확한 중앙값보다는 범위 수치에 만족한다. 이 특정 사례에서는 문헌에서 알려진 알고리즘을 사용할 수 있다.예를 들어 업데이트, 병합, 최종화 작업을 지원하는 스케치를 제공하거나, 후속 작업은 꼬리 값(예: 99.9번째 백분위수)에 맞춰 조정된 동일한 문제를 해결한다. 히스토그램 추적을 위해 오픈 소스 Deequ 패키지에서 구현이 가능한데 이 구현은 JSON 형식으로 내부 변수를 직렬화할 수 있는 해석 가능한 스케치를 제공한다. 이는 사용자 지정 코드를 실행하거나 이 스케치의 메커니즘을 이해하려는 사용자에게 유용한 속성이다. 스케치를 통해 추적할 수 있는 다양한 지표가 있다. 모든 지표에 대한 스케치를 제공하지는 않으며 제공할 수도 없기 때문에 데이터 포인트 샘플을 유지한다. 이는 사용자에게 있는 그대로 유용하며, 언급된 지표, 사용자 지정 지표 또는 알려진 스케치가 없는 지표에 대한 '포괄적인' 스케치로 볼 수 있다.표본 외에 다른 것이 왜 필요한지 의문이 들 수 있다. 정답은 표본에 대한 지표를 계산하면 근사값만 얻을 수 있다는 것이다. 스케치를 사용하면 근사값 히스토그램처럼 더 적은 리소스(계산 및 저장 공간 모두)로 더 정확한 답을 얻을 수 있으며 정확한 답을 얻을 수도 있다.
4-2. 메트릭 및 그 용도
이러한 메트릭을 추적하면 단순한 통계 모니터링 이상의 기능을 제공한다. 이상 탐지 및 드리프트 탐지와 같은 더욱 정교한 사용 사례가 가능하다. 이상 탐지의 경우, 가우시안 분포를 따르는 숫자형 변수를 모니터링하는 경우 평균과 표준 편차를 추적하여 평균에서 표준 편차가 너무 큰 개별 값을 강조 표시하여 이상 탐지를 수행할 수 있다.물론 이상 탐지를 위한 다른 많은 기법이 있다. 일부는 저장된 메트릭에서 사용 가능한 정보를 기반으로 수행할 수 있으며, 다른 기법은 샘플을 사용하거나 자체 스케치를 사용하여 스트림에 연결해야 한다. 랜덤 컷 포레스트(Random cut forest)는 자체 상태를 유지하는 이상 탐지 알고리즘의 한 예이다. 여기서 finalize 연산은 입력으로 데이터 포인트를 필요로 하고 내부 상태를 사용하여 이상 점수를 제공한다. 드리프트 탐지를 위해서는 관찰 결과를 따르고, (i) 비전문가도 직관적으로 조정하고 이해할 수 있고, (ii) 두 분포가 다를 확률을 탐지할 뿐만 아니라 그 거리도 측정할 수 있는 테스트를 목표로 한다. (ii)의 경우에는 드리프트 탐지를 위한 기존 방법은 "컬렉션 A가 컬렉션 B와 동일한 분포에서 추출될 가능성은 얼마나 될까?"라는 질문에 대한 답을 찾는 것을 목표로 한다. 이러한 시나리오에서는 통계적 측면이 필요하지 않으며 "컬렉션 A의 분포와 컬렉션 B의 분포 사이의 거리가 임계값보다 큰가?"라는 질문에 대한 답을 찾을 수 있다.
4-3. 모델 공정성 및 편향 통계의 드리프트 감지를 위한 응용 프로그램
알고리즘 편향, 차별, 공정성 및 관련 주제는 법률, 정책 및 컴퓨터 과학과 같은 여러 분야에서 연구되어 왔다. 자동화된 의사 결정 모델은 특정 특징 또는 특징 그룹을 차별하는 경우 편향된 것으로 간주될 수 있다. 이러한 응용 프로그램을 구동하는 ML 모델은 데이터로부터 학습하며, 이 데이터는 불균형이나 기타 내재적인 편향을 반영할 수 있다. 예를 들어, 학습 데이터는 다양한 특징 그룹을 충분히 표현하지 못하거나 편향된 레이블을 포함할 수 있다.
공정성에 대한 다양한 개념에 따라 편향을 측정하는 여러 지표가 있다. 공정성에 대한 단순한 개념을 고려하더라도 다양한 맥락(예: 규정, 법률, 윤리 원칙 등)에 적용 가능한 다양한 측정 기준이 있다. 예를 들어 성별이나 연령에 따른 공정성을 고려하고, 단순화를 위해 크기가 거의 같은 두 개의 관련 클래스가 있다고 가정해 보겠다. 대출을 위한 ML 모델의 경우, 두 계층 모두에 동일한 수의 중소기업 대출이 발행되기를 원할 수 있다. 또는 구직자를 처리할 때 각 계층의 구성원이 동일한 수로 고용되기를 원할 수 있다. ML 모델의 초기 편향을 측정하는 것은 첫 단계일 뿐이며, 시간이 지남에 따라 모델이 공정성을 유지할 것이라고 보장하기에는 충분하지 않다. 실제로, 입력 데이터 분포의 변화로 인해 모델이 편향될 수 있으며, 적절한 모니터링 시스템이 없으면 편향된 자동 예측이 생성될 수 있다.이 문제를 해결하기 위해 Model Monitor는 다양한 공정성 지표를 제공한다.
4-4. 모델 특징 속성의 드리프트 감지
LIME 및 SHAP과 같은 특징 귀속 방법은 개별 입력 특징에 대한 중요도 점수, 즉 특징이 모델 예측에 얼마나 중요한지를 제공한다. 이러한 점수는 인스턴스 수준 또는 전역 데이터 세트 수준에서 계산할 수 있다.특징 귀속 점수의 변화는 기반 데이터의 변화를 나타낼 수 있으며, 결과적으로 새 데이터에 대한 모델의 정확도를 나타낼 수 있다. 특징 귀속의 드리프트는 실제 레이블을 수집할 필요 없이 모델 정확도의 잠재적 저하를 조기에 알릴 수 있는데, 실제 레이블 수집은 시간과 비용이 많이 드는 작업이다.
Model Monitor의 특징 귀속 드리프트 감지 기능은 SageMaker Clarify의 특징 귀속 기능을 기반으로 한다. Clarify를 사용하면 사용자는 입력, 모델이 배포된 엔드포인트 주소, SHAP 알고리즘 매개변수를 지정하여 SHAP 피처 속성을 계산할 수 있다. Model Monitor는 또한 지정된 기간 동안 모델 입력/출력을 캡처하여 시간 경과에 따른 속성 변화를 감지하는 기능을 제공한다. 개별 피처의 순위가 학습 데이터에서 추론 데이터로 어떻게 변경되었는지 비교하여 드리프트를 감지할 수 있다. 순위 순서의 변화에만 민감하게 반응하는 것 외에도 피처의 원시 속성 점수에도 민감하게 반응해야 한다. 예를 들어, 학습 데이터에서 추론 데이터로 이동할 때 순위에서 같은 수의 위치만큼 순위가 떨어지는 두 피처가 있는 경우, 학습 데이터에서 속성 점수가 더 높은 피처에 더 민감하게 반응해야 한다. 이러한 속성을 염두에 두고, 학습 데이터와 추론 데이터의 피처 속성 순위를 비교하기 위해 정규화된 할인 누적 이득(Normalized Discounted Cumulative Gain; NDCG) 점수를 사용하는데 1이 가장 좋은 값이다. NDCG 값이 1이면 추론 데이터의 특성 귀속 순위가 학습 데이터의 특성 귀속 순위와 동일함을 의미한다. NDCG 값이 0.9 미만으로 떨어지면 모델 모니터에서 자동으로 알림을 발생시킨다.
5. 적응형 재학습
사용자들이 흔히 제기하는 시나리오는 모델 재학습의 필요성이다. 모델 성능을 유지하기 위해 정기적으로 빈번하게 모델을 재학습하는 것이 일반적이다. 이러한 재학습 절차는 학습을 위한 컴퓨팅 리소스와 기존 모델을 새 모델로 점진적으로 교체하는 데 드는 간접비 때문에 비용이 많이 들 수 있다. 사용자는 배포된 모델의 품질을 모니터링하고 필요할 때만 재학습하기를 원한다. 이러한 재학습의 실제 가치는 시나리오마다 다르다.
시스템은 이를 더 잘 추적하기 위해 재학습 시기를 선택할 수 있으며 오류에 따라 재학습하는 적응형 시스템과 정기적으로 재학습하는 비적응형 시스템의 비용(재학습 횟수) 대비 오류(RMSE)를 측정한다.
그림 2는 서로 다른 난수 시드를 사용하여 반복 실험한 시스템의 산점도를 보여준다. 막대는 동일한 비용을 가진 모든 실험에 대한 평균 RMSE를 나타낸다. RMSE 손실 대 발생 비용을 그래프로 표시하는데 점들은 개별 실험을 나타낸다. 막대는 주어진 방법에 대해 동일한 비용으로 모든 점에 대한 평균 RMSE를 나타낸다. 적응형 시스템이 훨씬 더 나은 트레이드오프를 제공한다는 것이 분명한다.
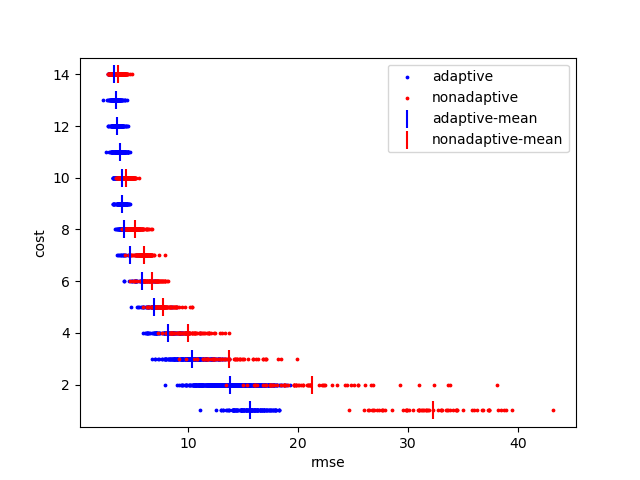
[그림2. 적응형 방법과 비적응형 방법의 비교]
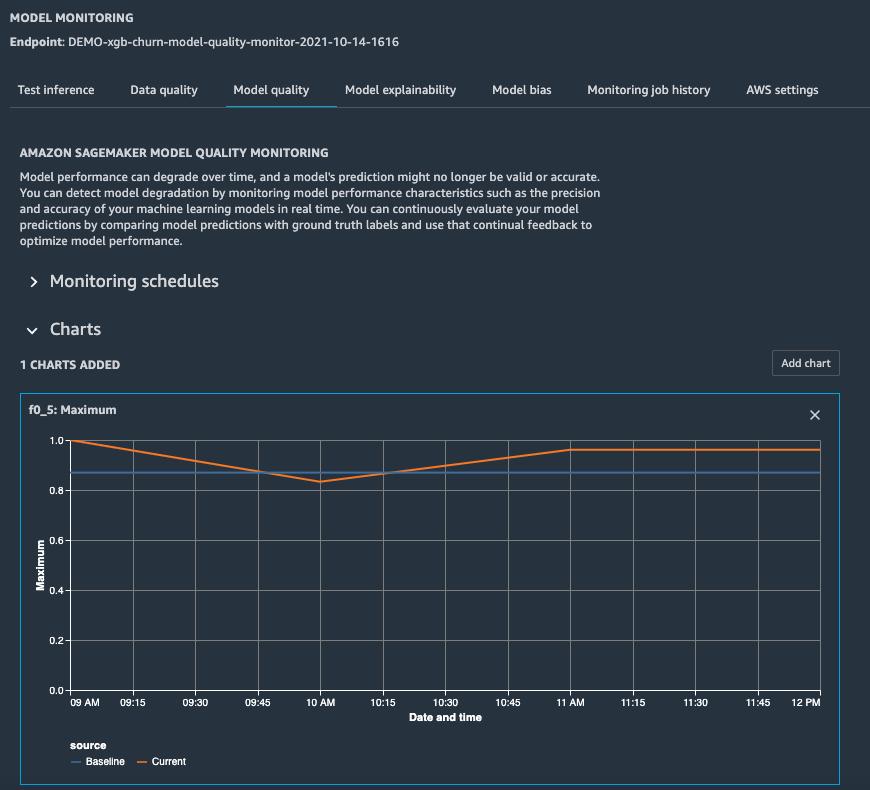
[그림3. 세이지메이커 스튜디오에서 이진 분류 모델에 대한 F0.5 점수의 모델 모니터 모델 품질 계산 결과]
6. 유즈케이스
유즈케이스로 Model Monitor의 두 가지 일반적인 사용 사례를 기술하면 다음과 같다.
6-1. 마켓 인텔리전스(Market Intelligence)
마켓 인텔리전스(Market Intelligence) 모델은 다양한 출처(예: 자사, 제3자, 설문 조사 데이터)의 다양한 입력 데이터를 기반으로 작동하며, 타겟 고객에게 더욱 효과적으로 서비스를 제공하는 데 사용된다. 이러한 모델은 자동차, 보험, 미디어 소비, 금융, 여행 등의 산업으로 확장된다. 이러한 모델의 성능은 데이터 드리프트(예: 입력 변수의 통계 변화) 및 개념 드리프트(예: 여러 변수 간의 관계 변화)로 인해 영향을 받을 수 있다.
이를 위해 Model Monitor는 데이터 유형 검사, 완전성 검사, 기준선 드리프트 검사, 누락된 열 검사, 추가 열 검사, 범주형 값 검사와 같은 규칙을 사용하여 데이터 드리프트를 감지한다. 예를 들어, 금융 기관에서 신청자의 대출 승인을 예측하는 데 사용하는 ML 모델을 적용할 수 있다. 이 모델을 학습할 때 나이는 특성으로 사용되며 항상 존재한다. 그러나 나중에 금융 기관은 대출 신청 시 나이를 선택 사항으로 지정할 수 있다.
이 경우, 모델 모니터는 실제 데이터에서 이러한 변경 사항을 감지하고 모델 유지 관리자에게 위반 사항이 경고된다. 모델 품질 모니터링은 모델이 예측한 값과 모델이 예측하려는 실제 기준 실측 레이블을 비교하여 모델의 성능을 모니터링한다. 모델 품질 모니터링 작업은 ML 문제 유형에 따라 다양한 지표를 계산한다. 여기에는 모델 정확도, 혼동 행렬, 재현율, 곡선 아래 면적(AUC), F1 점수 및 F2 점수가 포함된다.
특정 지표가 기준 설정 작업에 의해 결정된 임계값을 초과하거나 미만으로 이동하면 위반이 발생하여 고객이 실제 데이터를 기준으로 모델 성능을 추적할 수 있다. 예를 들어, 앞에서 기술한 대출 승인 예측 모델을 고려하면 다음과 같다. Freddie Mac에 따르면, 11개의 주택담보대출 금리는 2018년 11월 이후 꾸준히 하락해 왔다. 다른 모든 조건이 동일하다면, 금리가 하락함에 따라 특정 소득에 대해 승인된 대출 금액은 월 상환액이 낮아지기 때문에 더 높아진다. 금리가 높았던 기간의 데이터 세트를 사용하여 학습된 모델은 실제 데이터보다 특정 소득 및 대출 금액에 대해 더 많은 대출 거부 예측을 수행한다. 이 경우, Model Monitor는 실제 데이터에서 이러한 변화를 감지하고 모델 유지 관리자는 F 점수의 발산에 대한 알림을 받을 수 있다.
6-2. 자연어 처리(NLP) 모델의 데이터 드리프트 감지
word2vec[24], BERT[6], RoBERTa[22]와 같은 자연어 처리(NLP) 인코더는 채팅봇 및 가상 비서부터 기계 번역 및 텍스트 요약에 이르기까지 다양한 응용 분야에서 사용된다.
이러한 인코더는 입력 단어 또는 단어 시퀀스를 단어 수준 임베딩으로 변환하여 작동한다. 이러한 임베딩은 다운스트림 작업별 모델에서 사용된다. 입력 텍스트 분포의 변화는 다운스트림 모델의 성능에 분명히 영향을 미칠 수 있다.
그러나 텍스트의 특정 구조로 인해 텍스트 데이터 모니터링은 까다로운 작업이다. 고정 차원과 경계가 있는 경우가 많은 표 형식 데이터와 달리 텍스트 데이터는 종종 자유 형식이다. 이러한 문제를 해결하기 위해 원시 텍스트 자체가 아닌 텍스트 데이터의 임베딩에 Model Monitor를 사용하기로 결정했다.
그림 4는 텍스트 데이터의 드리프트를 감지하기 위한 사용자 지정 모니터링 일정을 구성하는 예를 보여준다.
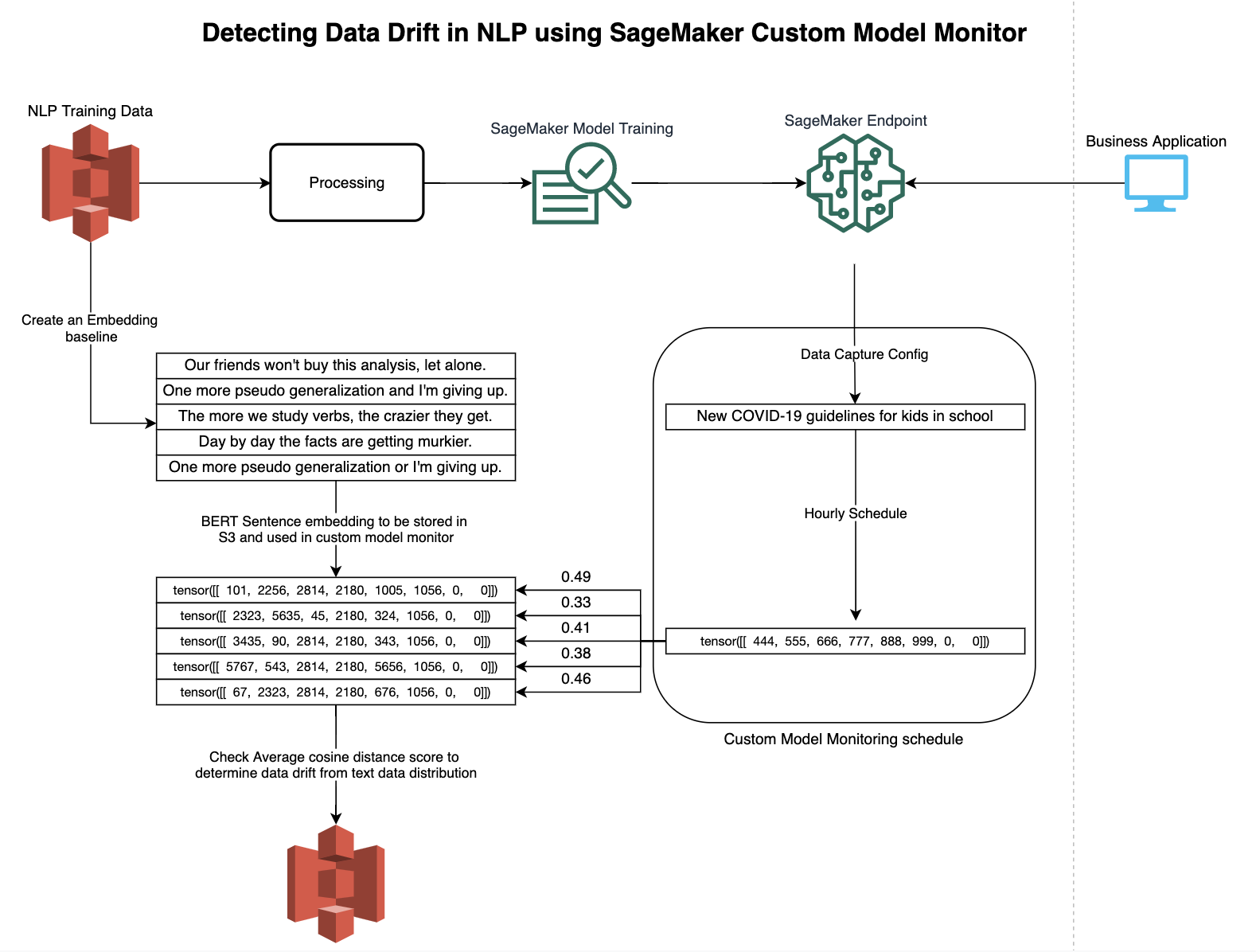
[그림4. Model Monitor에서 사용자 지정 모니터링 일정을 사용하여 NLP 모델에서 데이터 드리프트 감지]
이 사용 사례에서는 Bring Your Own Container(BYOC) 방식으로 데이터 드리프트를 감지하는 방법을 보여준다. 이 예에서는 BERT 인코더에서 시작하여 작업별 계층을 그 위에 추가한다. 대상 작업에 대한 학습 데이터 세트가 주어지면 작업별 계층을 학습하는 것 외에도 BERT 인코더를 선택적으로 미세 조정할 수 있다. Model Monitor를 사용하여 매시간 실행되는 모니터링 일정을 설정하여 데이터 드리프트를 지속적으로 모니터링한다. 위반 사항이 감지되면 CloudWatch 알림과 SNS 알림을 전송하여 고객이 모델을 재학습할 수 있도록 한다.
6-3. 배포단계에서 인사이트
모델 모니터링은 중요하고 모든 ML 기반 시스템 프로덕션 배포에 광범위하게 적용 가능하므로, 금융 서비스, 자동차, 소프트웨어, 통신, 소매 등 다양한 산업 분야의 전 세계 고객이 Model Monitor를 사용하고 있다.
- 시작 단계 개선: Model Monitor는 모니터링 설정을 위해 주로 프로그래밍 방식 인터페이스를 사용하여 출시되었다. 출시 후 고객 인터뷰를 통해 인터뷰 대상자의 약 6분의 1이 모니터링 설정에 그래픽 인터페이스를 사용하는 것을 선호했으며, 프로그래밍 방식 인터페이스와의 기능 동등성이 중요함을 확인했다. 이러한 피드백을 바탕으로, 모니터링을 활성화하고 합리적인 기본값을 선택하여 대부분의 옵션을 숨기면서도 사용자가 필요에 따라 이를 재정의할 수 있도록 하는 그래픽 기반 안내 프로세스를 개발이 가능하다.
- 표 형식 데이터 외의 사용 편의성: 표 형식 ML 사용 사례에 대한 기본 노코드 환경을 제공하는 것이 가능하다. 하지만 고객은 테이블 형식 모델 외에도 이미지 분류 모델이나 NLP 모델과 관련된 메트릭 모니터링과 같은 다양한 사용 사례를 활용할 수 있다. Model Monitor는 분석 컨테이너를 제공하여 확장 가능하도록 설계되었지만, 고객 3명 중 1명만이 이러한 방식을 선택한다. 이러한 고객은 Model Monitor와 같은 솔루션을 선택하여 연구 결과를 턴키 환경에 직접 적용할 필요가 없다. 맞춤형 Docker 이미지 지원을 활용하여 고객이 이러한 사용 사례에서도 Model Monitor를 사용할 수 있는 방법을 보여주는 문서와 블로그 게시물을 제작을 통해 고객의 편이성을 높일 수 있다.
- 데이터 증강을 위한 후크 - 사전/사후 처리 후크: 초기 구현에서는 Endpoint에서 캡처한 데이터에 대해 직접 모델 모니터 분석이 가능하다. 일반적으로 고객이 직접 분석할 수 없는 데이터를 프로덕션 환경에서 전송하는 것으로 나타났다. 추론 페이로드는 Endpoint에 압축되어 전송되거나 실제 ML 모델에서 사용하는 원핫 인코딩과 같은 변환 없이 전송될 수 있다. 또한, 결과가 저장되는 형식을 조정해야 할 수도 있다. 이에 따라 분석 전후에 사용자 지정 로직을 수행할 수 있도록 전처리 및 후처리 후크를 추가했다. 현재 거의 절반의 고객이 이 기능을 사용하여 입력 및 출력 데이터를 필요한 형태로 보강하고 있다.
- 편향 및 특성 귀속 드리프트: 2019년 12월 출시된 초기 제품은 데이터 드리프트 모니터링에 중점을 두었다. 고객들은 배포된 모델의 품질을 전체적으로 모니터링할 뿐만 아니라 여러 그룹에서 모델의 예측 동작에 새로운 차이가 있는지 파악하고 싶어한다. 초기 데이터나 모델에 편향이 없더라도, 실제 상황의 변화로 인해 이미 훈련된 모델에 시간이 지남에 따라 편향이 발생할 수 있다. 예를 들어, 주택 구매자 인구 통계에 상당한 변화가 있을 경우, 특정 인구가 원래 훈련 데이터에 존재하지 않는 경우 주택 대출 신청 모델이 편향될 수 있다.이러한 과제를 해결하기 위해 2020년 12월 SageMaker Clarify와 통합하여 Model Monitor의 기능을 확장했다. 이를 통해 모델 소유자는 편향 및 특성 속성의 변화를 모니터링하고 알림에 따라 시정 조치를 취할 수 있게 되었다.
7. 결론
본 원고에서는 고품질 머신 러닝 모델이 배포된 후에도 유지 관리되어야 한다는 필요성을 고려하여, Amazon SageMaker Model Monitor를 리뷰했다. 이 시스템은 모델의 데이터, 개념, 편향 및 특성 귀속 드리프트를 실시간으로 자동 감지하고 모델 소유자가 시정 조치를 취할 수 있도록 알림을 제공한다. Model Monitor의 주요 설계 고려 사항과 기술 아키텍처를 데이터 수집, 데이터 분석, 작업 스케줄링의 세 가지 측면에서 기술하였고 데이터 드리프트 감지 방법론과 모델 편향 지표 및 특성 귀속 드리프트 감지를 위한 적용, 사례 연구, 일반적인 사용 사례, 배포 인사이트에 대하여 살펴보았다. 머신러닝 시스템이 주요 산업에 도입됨에 따라 배포 후 모델의 성능을 보장하는 것은 자연스럽게 중요한 영역이며, 프로덕션 환경에서 모델을 모니터링하는 것은 솔루션의 핵심 부분이다.
Amazon SageMaker Model Monitor를 도입하면 머신러닝 모델의 예측 품질과 운영 안정성을 지속적으로 유지하고 향상시킬 수 있다. 모델이 실제 운영 환경에 배포된 이후에도 입력 데이터의 분포, 출력 예측값, 성능 지표 등의 변화를 자동으로 모니터링하여 데이터 드리프트, 피처 드리프트, 콘셉트 드리프트와 같은 문제를 조기에 감지할 수 있다. 이를 통해 모델 성능 저하를 사전에 파악하고 적절한 조치를 취함으로써, 비즈니스 의사결정에 미치는 영향을 최소화할 수 있다.
또한 SageMaker Model Monitor는 이상 탐지를 자동화하고 알림 및 로그 기록 기능을 제공하므로, 운영자가 수동으로 데이터를 분석하거나 일일이 모니터링하지 않아도 되어 운영 효율성을 크게 높일 수 있다. 더불어 규제 준수나 감사 목적의 관점에서도 모델 예측에 대한 지속적인 기록과 추적 가능성을 확보할 수 있어, 신뢰성과 투명성을 강화할 수 있다. 이러한 기능은 특히 금융, 의료, 제조 등 고신뢰성과 규제가 요구되는 산업에서 중요한 역할을 한다. Amazon SageMaker Model Monitor의 업종별 기대효과는 산업 특성에 따라 다음과 같다.
1) 금융 (예: 은행, 보험, 핀테크)
- 사기 탐지 모델의 정확성 유지: 거래 패턴이 급변하거나 새로운 유형의 사기 수법이 등장하는 경우, 데이터 드리프트를 빠르게 감지하여 모델 성능 저하를 예방할 수 있다.
- 규제 준수 강화: AML(자금세탁방지), 신용 평가 등 규제 영역에서 모델 예측의 투명성과 재현성을 보장해 감사 대응력을 향상시킨다.
- 실시간 리스크 관리: 고객 행동 및 시장 변동 데이터를 기반으로 한 리스크 평가 모델을 실시간으로 모니터링해 정확한 의사결정을 지원한다.
2) 의료·헬스케어
- 진단 및 예측 정확도 유지: 환자의 건강 상태나 진단 기준이 시간에 따라 변할 수 있기 때문에, 드리프트 탐지를 통해 모델이 계속해서 유효한 결과를 내는지 확인할 수 있다.
- 환자 안전 보장: 잘못된 예측이 치명적인 결과를 초래할 수 있는 의료 분야에서, 모델의 이상 징후를 조기에 발견하여 의료 과실 리스크를 줄인다.
- 규제 및 데이터 감사 대응: HIPAA 등 개인정보 및 의료데이터 규제 준수를 위한 로깅 및 모니터링 기능을 제공한다.
3) 제조·스마트팩토리
- 품질 예측 모델의 안정성 유지: 생산 설비나 원재료의 특성이 변화하는 경우에도 모델이 정확한 예측을 지속할 수 있도록 상태를 모니터링한다.
- 설비 고장 예측 정확도 향상: 예지 정비(Predictive Maintenance) 모델이 지속적으로 고장 징후를 잘 포착하는지 실시간 확인이 가능하다.
- 운영 효율 최적화: 공정 최적화 모델이 환경 변화에 따라 부정확해지는 것을 방지하고, 생산성 향상을 지속적으로 달성한다.
4) 유통 및 전자상거래
- 수요 예측 및 추천 시스템 품질 유지: 계절성, 프로모션, 소비 트렌드 변화에 따른 입력 데이터의 변화를 탐지하여 수요 예측 및 개인화 추천의 정확성을 유지한다.
- 이탈 예측 모델의 민감도 유지: 고객 행동이 변하는 시점에 이탈 예측 정확도가 떨어지는 것을 방지하여 마케팅 전략의 효과를 극대화할 수 있다.
- 광고 최적화 모델의 신뢰성 확보: 클릭률, 전환율 등 광고 성과 모델의 품질을 지속적으로 모니터링하여 예산 효율을 최적화한다.
5) 공공 및 에너지
- 에너지 수요 예측의 정확성 향상: 날씨, 계절, 지역별 사용패턴 변화 등을 반영한 모델 성능 저하를 조기에 탐지하여 효율적인 에너지 공급 계획 수립이 가능하다.
- 이상 탐지를 통한 안전 강화: 발전소, 스마트 그리드에서의 센서 이상 데이터를 빠르게 감지하여 안전사고를 예방한다.
- 정책 분석 및 시민 서비스 개선: 예측 모델 기반의 정책 시뮬레이션이 정확한 데이터 기반에서 운영되도록 보장한다.
궁극적으로 SageMaker Model Monitor의 도입은 머신러닝 모델의 생명주기 관리(MLOps)를 체계화하고, 예측 서비스의 품질을 지속적으로 보장함으로써 기업의 AI 도입 효과를 극대화하는 데 기여한다.
참 고 문 헌
- Amazon Web Services. (2024). Monitor Models for Drift with Amazon SageMaker Model Monitor
- Amazon Web Services. (2023). Amazon SageMaker Developer Guide – Model Monitoring
- Amazon Web Services. (2021). MLOps: Continuous delivery and automation pipelines in machine learning
- Evidently. Evidently AI: open-source machine learning monitoring, 2022.
- Fiddler. Explainable monitoring = high-performance, 2021. Accessed: 2021-10.
- Clarify, S. Create feature attribute baselines and explainability reports, 2021. Accessed: 2021-10-07.
- Edwards, J., et al. MLOps: Model management, deployment, lineage, and monitoring with Azure Machine Learning, 2021. Accessed: 2021-10. IBM. Validating and monitoring AI models with Watson OpenScale, 2021. Accessed: 2021-10.
- Lipton, Z., Wang, Y.-X., and Smola, A. Detecting and correcting for label shift with black box predictors. In International Conference on Machine Learning (2018), PMLR, pp. 3122-3130.
- Ribeiro, M. T., Singh, S., and Guestrin, C. "Why should I trust you?" Explaining the predictions of any classier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (2016), pp. 1135-1144.
저작권 정책
SaaS 전환지원센터의 저작물인 『배포된 머신 러닝 모델에 대한 실시간 통찰력을 제공하는 Amazon SageMaker Model Monitor』은 SaaS 전환지원센터에서 상명대학교 서광규 교수에게 집필 자문을 받아 발행한 전문정보 브리프로, SaaS 전환지원센터의 저작권정책에 따라 이용할 수 있습니다. 다만 사진, 이미지, 인용자료 등 제3자에게 저작권이 있는 경우 원저작권자가 정한 바에 따릅니다.
