
클라우드 전문정보
| 제목 | AIOps 플랫폼 사례 | ||
|---|---|---|---|
| 등록일 | 2022-09-19 | 조회수 | 3246 |

베스핀글로벌 / 윤영기 이사
1. 개요
AIOps(Artificial Intelligence for IT Operations) 플랫폼은 다양한 데이터에 대한 광범위한 분석을 제공하여 주요 프로세스, 작업, 의사 결정 등을 개선할 수 있도록 한다. 또한 빠른 양의 데이터 수집을 자동화하고 머신 러닝을 활용하여 데이터를 분석하고 결과를 제시함으로써 문제를 예측 및 경고 또는 조언하여 사용자가 사전 예방적 의사 결정을 내릴 수 있도록 지원한다.
이를 위해 AIOps 플랫폼은 다음과 같은 기능을 제공할 수 있어야 한다.
- 개발팀 및 IT운영팀 내의 기존 도구 등 여러 소스에서 데이터를 엑세스하고 수집하는 기능
- 관련 데이터를 저장하는 기능
- 기계 학습 알고리즘을 사용하여 실시간 및 과거 데이터를 분석하는 기능
- 데이터 분석을 통한 규범적 응답 및 통찰력을 제공하는 기능
- 자동 개선 또는 작업 도구와의 통합
- 통찰력을 위한 대시보드
2. AIOps 플랫폼 사례 분석
2.1 Service Now ITOM
Service Now의 ITOM은 서비스 자동 식별 및 구성관리(CMDB)를 통한 Service Map, 이벤트 수집 및 기계학습을 통한 Anomaly Detection 및 Root Cause 분석기능을 제공하는 인공지능 기반의 IT운영관리 플랫폼이다.
- CI(Configuration Item)를 그룹핑한 Service라는 개념을 적용하여 인시던트 식별/관리를 Service단위로 할 수 있다.
- CI를 자동으로 식별하고 그 정보를 체계적으로 관리할 수 있는 Discovery 기능과 CMDB 기능을 제공한다.
- Data분석을 통해 장애에 대한 장애원인을 쉽게 알 수 있도록 Root Cause 정보를 제공하고 필요 시 Auto Remediation 기능을 이용하여 화면상에서 바로 조치를 취할 수 있다.
데이터 수집
Agent기반의 data collector는 설치된 장치에서 명령을 실행하고 MID Server (Manager Instrumentation and Discovery)를 통해 ServiceNow에 이벤트와 메트릭을 전송한다.
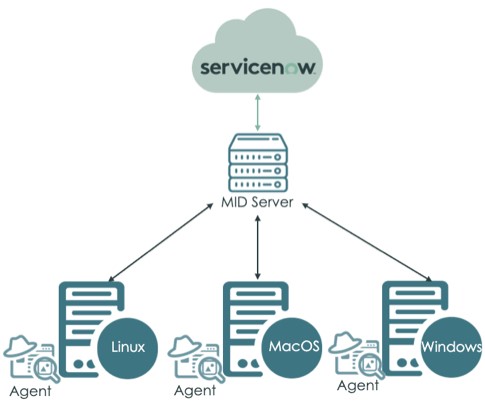
[그림. ServiceNow ITOM Agent Client Collector 구성]
Anomaly Detection
패턴 검색으로 데이터의 고유 행동을 식별, 새롭게 발생한 문제를 빠르게 탐지한다.
- 로그, 추적 및 메트릭의 정상적인 작동 패턴을 식별한다.
- 모니터링 도구에서 원시 메트릭을 수집하여 성능 이상이 있을 때 CI에 대해 이벤트를 발생한다.
Root Cause분석
Alert의 근본원인이 되는 항목을 분석하여 원인목록을 제공한다.
- 원인 식별 기준 : CI변경, 애플리케이션 변경, 기타 Alert내용 식별한다.
Remediation
기계학습을 통해 반복되는 경고와 유사한 과거 경고를 식별하여 관련 기술자료를 기반으로 교정조치(Actions)를 제공하며 교정 가능한 조치일 경우 이를 포털에서 실행하여 문제를 즉시 해결할 수 있다.
Topology
MID서버를 통해 수집된 Infra 및 Application를 CMDB와 매핑하여 Map형태로 제공하며, Topology상의 Service는 CMDB를 통해 Alert과 CI간 상호 연결된다.
Service 맵핑방식은 4가지를 지원한다.
- AI기반 예측 검색
- 패턴에 따라 자동으로 검색
- 태그기반 검색
- 트래픽 기반 검색
Dashboard
전체 리소스를 Service 단위로 Overview하여 보여주며, 인시던트 발생 시 심각도(Severity)에 따라 해당 Service가 색상으로 구분되어 표시되기 때문에 리소스의 이상 상태를 쉽게 확인할 수 있다.
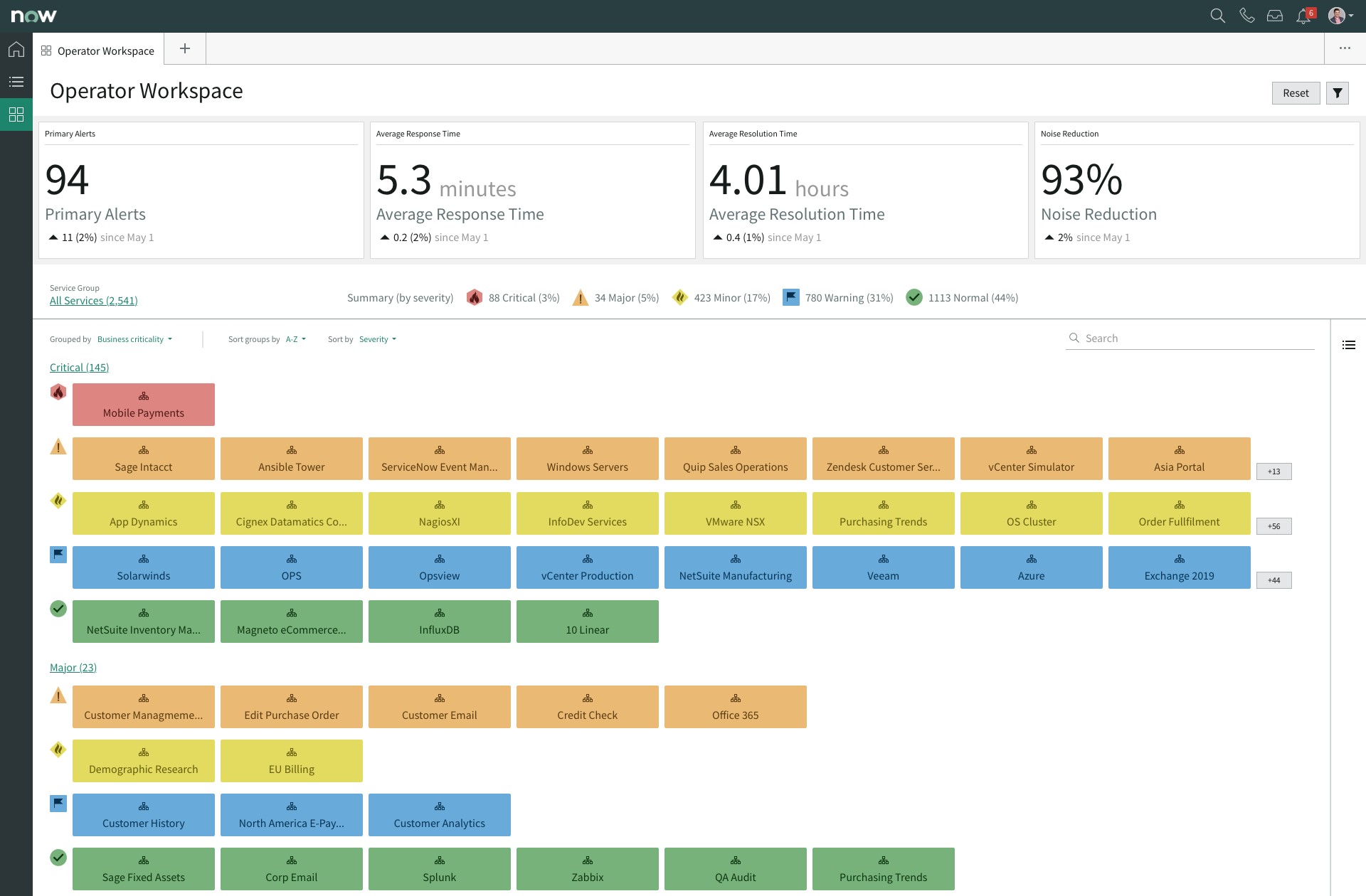
[그림. ServiceNow ITOM Dashboard]
2.2 Tanzu Observability
Tanzu Observability는 다양한 이벤트 차트를 만들어 사용자가 원하는 정보를 모니터링 하는 이벤트 모니터링 솔루션에 조금 더 가깝다.
- 50여 개의 Dashboard Template과 커스텀 Dashboard 기능 제공
- 인프라 외 Kubernetes 모니터링 기능과 Application Map 및 Tracing 정보를 제공한다.
데이터 수집
Tanzu Observability는 Agent 또는 API호출방식을 통해 다양한 SW 및 클라우드 서비스의 데이터 수집 방법을 제공한다.
Alert Management
발생된 Alert의 목록과 매트릭 정보를 확인할 수 있으며, 해당 얼럿의 상세 매트릭정보와, 동시에 발생된 관련 얼럿을 확인할 수 있다.
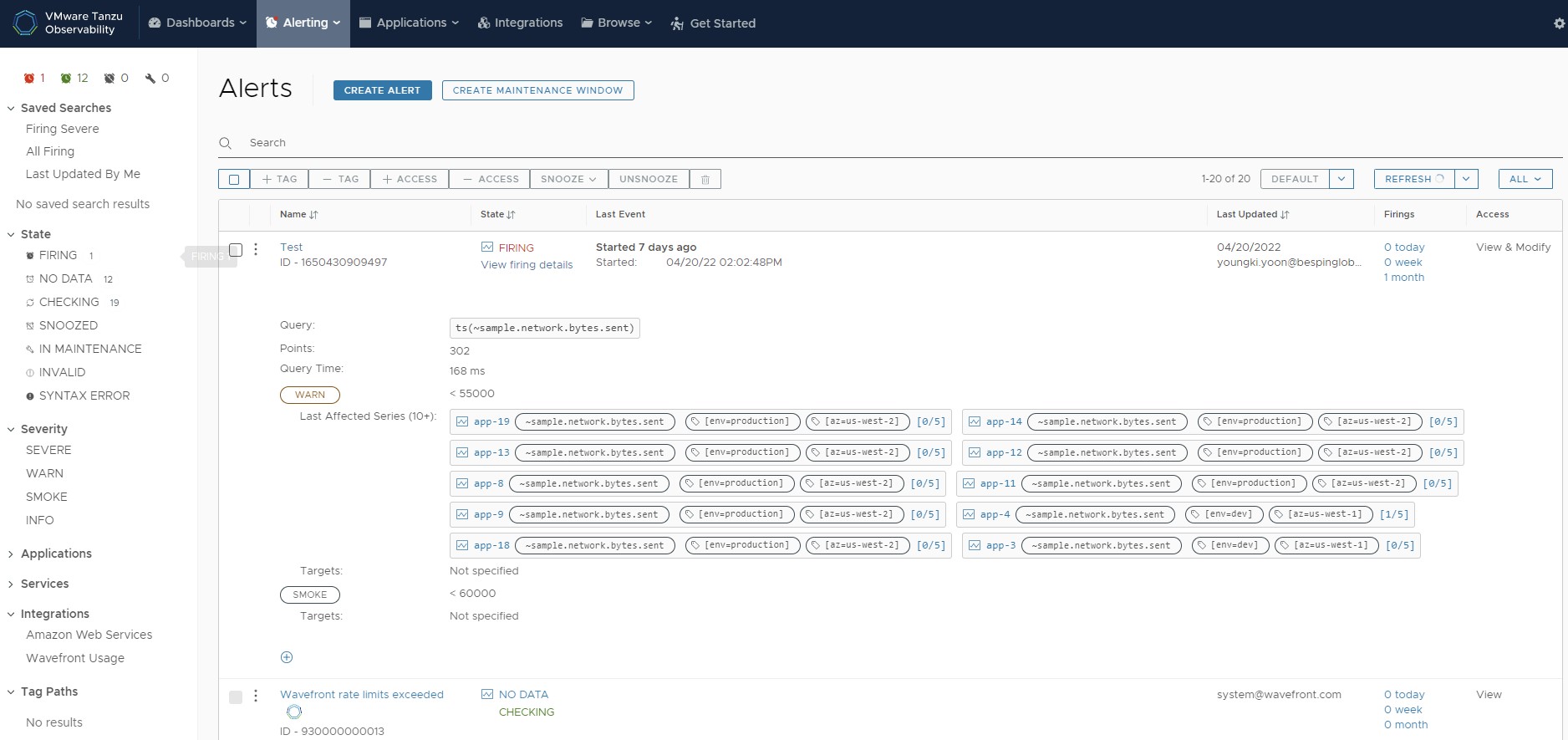
[그림. Tanzu Observability Alerts]
Anomaly Detection
사용자가 디스플레이 설정, 샘플 데이터 기간, 이상 유형 및 민감도를 지정하면 차트에서 해당 기간의 데이터를 분석하여 이상감지를 식별한다.
Topology
오픈소스 Tracing 툴인 OpenTelemetry연동을 통해 Trace정보를 수집하고, Application Map 과 Application간의 Tracing 정보를 제공한다.
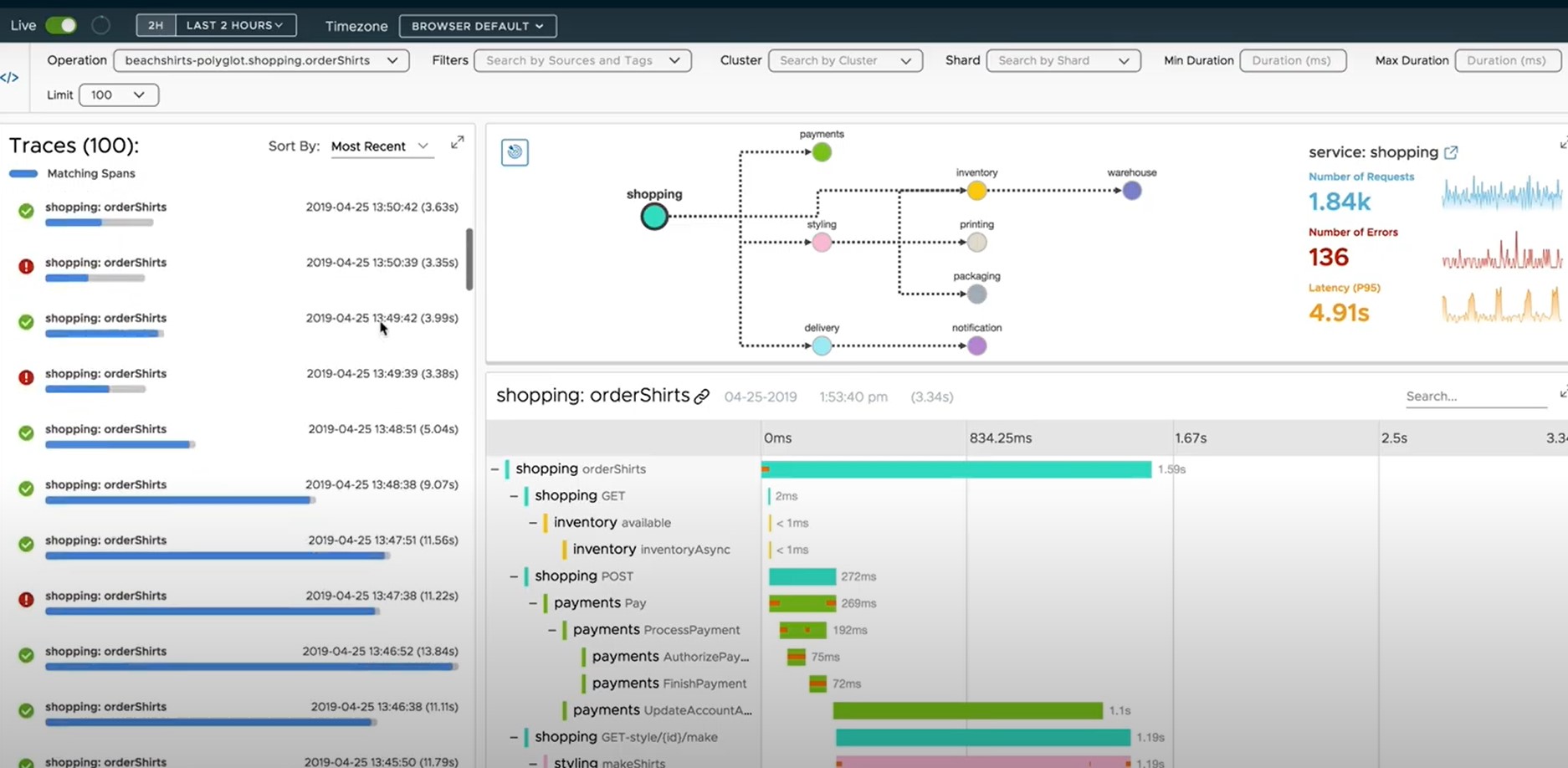
[그림. Tanzu Observability Topology]
Dashboard
50여개의 다양한 Dashboard 템플릿을 이용하여 사용자는 원하는 형태의 Dashboard를 자유롭게 구성할 수 있으며, 사용자 커스텀 Dashboard 구성도 가능하다.
2.3 IBM Cloud Pak Watson AIOps
IBM의 AIOps 플랫폼은 Watson을 활용한 AI 분석 알고리즘, ChatOps를 활용한 이벤트 통지/관리 등 기기능 제공하는 것이 특징이다.
- Slack, MS teams를 활용한 인터렉티브한 이벤트 관리 (ChatOps)
- 로그정보 자연어 처리 기반의 이상감지 기능 제공
- Runbook을 활용한 문제해결 제시
Anomaly Detection
자연어 처리 이상감지 방식과 통계기준선 로그 이상감지의 두 가지 알고리즘을 제공하며, 사용자가 선택하여 적용 가능하다.
- 자연어 처리 이상감지: 많은 로그데이터를 이용한 학습과정을 통해 자동으로 로그 구분을 분석하여 이상을 감지
- 통계기준선 로그 이상감지: 오류 코드 및 예외를 나타내는 짧은 텍스트 문자열과 같은 특정 엔터티를 로그에서 추출하고 각 구성 요소의 로그 수와 같은 다른 통계와 결합하여 이를 기준으로 사용하여 라이브 로그 데이터의 비정상적인 동작을 발견
Root Cause분석
인시던트가 발생하면 과거의 인시던트에 대한 세부 정보를 검토하여 현재 문제에 대한 해결 방법을 제시한다. 과거에 발생했으며 현재 애플리케이션에 영향을 미치는 유사한 메시지, 예외 및 티켓 내 이벤트에 대한 세부 정보를 검색하여 이전 인시던트를 수정하는 데 사용된 단계를 추출해준다.
Remediation
Runbook을 활용하여 문제를 해결할 수 있는 가이드를 제공한다.
운영절차를 Runbook으로 생성한 후 Runbook의 트리거 조건을 설정하면, 트리거 조건에 따른 Alert 발생 시 Runbook을 제시하는 방식으로 동작한다.
ChatOps
IBM은 특히 ChatOps개념을 도입하여 Slack, MS Teams등 Chat 도구 기반의 인터렉티브한 이벤트 관리기능 제공한다.
ChatOps를 확인할 수 있는 정보는 Anomaly Detection, 연관된 얼럿 및 인시던트, 인시던트에 영향을 받는 리소스 범위, 과거 유사한 인시던트 및 작업 제안 등이다.
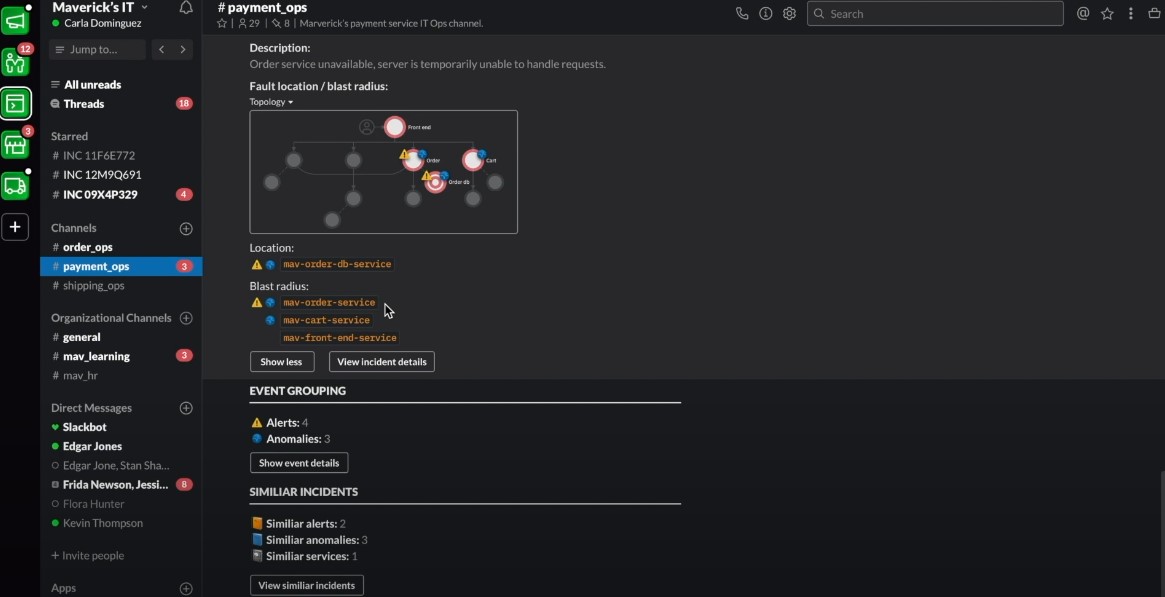
[그림. IBM AIOps의 ChatOps 장면]
Topology
IBM AIOps는 Topology를 통해 애플리케이션과 인프라에 대한 가시성 함께 제공한다.
Topology 뷰에서 원하는 시드 리소스를 검색하여 선택하면, 해당 리소스와 연관된 애플리케이션 및 인프라를 자동으로 랜더링하여 토폴로지를 구성해준다.
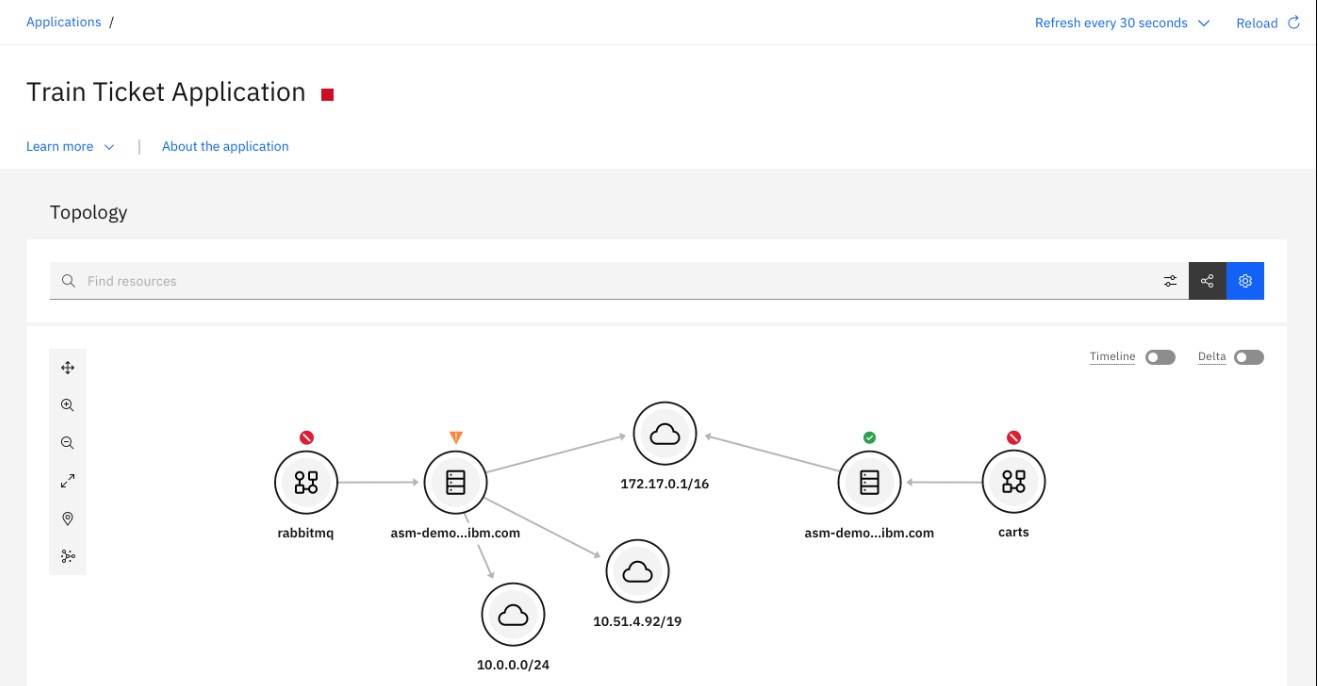
[그림. IBM AIOps의 Topology 뷰]
3. AIOps에서 Data는 어떻게 흘러가는가?
그렇다면, IT운영의 통찰력을 얻기 위한 Topology, Anomaly Detection, Root Cause, Remediation 정보를 제공하기 위해서, 수집된 데이터는 어떤 과정으로 처리되는 걸까? IBM의 AIOps Architecture를 살펴보자.
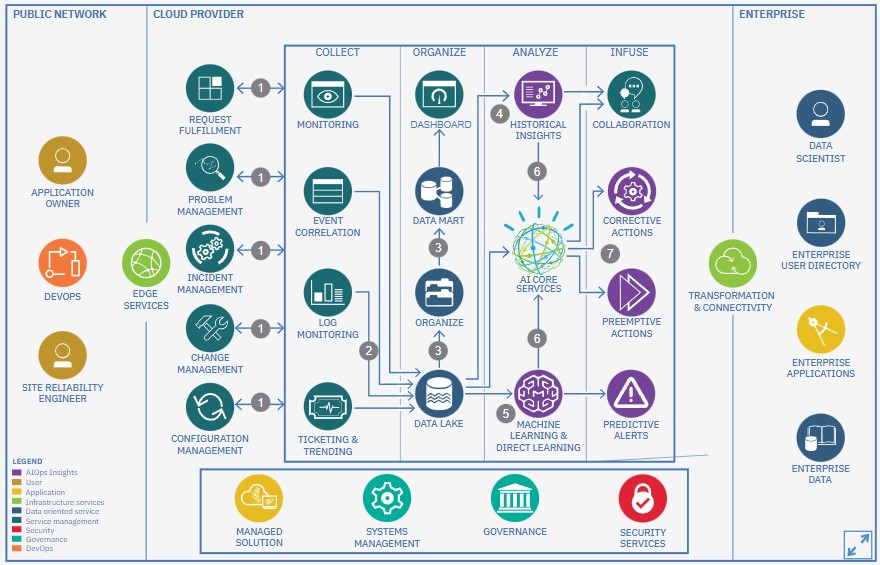
[그림. IBM AIOps Architecture]
Step1 ~ Step2. 서비스 요청, 인시던트관리, 변경관리, 구성관리 과정에서 발생하는 모니터링정보, 이벤트, 로그, 티켓정보 등이 실시간으로 Data Lake로 적재된다.
Step3. Data Lake에 들어간 데이터를 선별하고 재구성하여 가치 있는 데이터로 변경된다. 이 과정을 ETL(추출, 변환, 적재)이라고도 한다.
Step4. 구조화된 데이터는 Data Mart에 배치된 후 문제해결 및 사후 분석을 위해 대시보드에 표현된다.
Step5. 데이터 사이언티스트 또는 데이터 분석가는 Data Lake의 정형 및 비정형 데이터를 사용하여 딥러닝 및 AI모델을 구축한다.
Step6. 보다 유용한 데이터 분석을 위해 자연어처리, TTS등 AI서비스를 이용하기도 한다.
Step7. 분석결과를 통해 문제에 대한 시정조치(Corrective action)나 선제적조치(preemptive action), 예측경고(predictive alert)를 보낸다.
참 고 문 헌
- VENDOR SECELTION MATRIX AIOPS PLATFORMS (RESEARCH IN ACTION 2022)
- AI for IT Operations reference architecture (https://www.ibm.com/)
- ServiceNow ITOM (https://www.servicenow.com/)
- Tanzu Observability (https://tanzu.vmware.com/)
- IBM Cloud Pak for Watson AIOps (https://www.ibm.com/)
저작권 정책
K-ICT 클라우드혁신센터의 저작물인 『AIOps 플랫폼 사례』는 K-ICT 클라우드혁신센터에서 베스핀글로벌 윤영기 이사에게 집필 자문을 받아 발행한 전문정보 브리프로, K-ICT 클라우드혁신센터의 저작권정책에 따라 이용할 수 있습니다.
다만 사진, 이미지, 인용자료 등 제3자에게 저작권이 있는 경우 원저작권자가 정한 바에 따릅니다.
